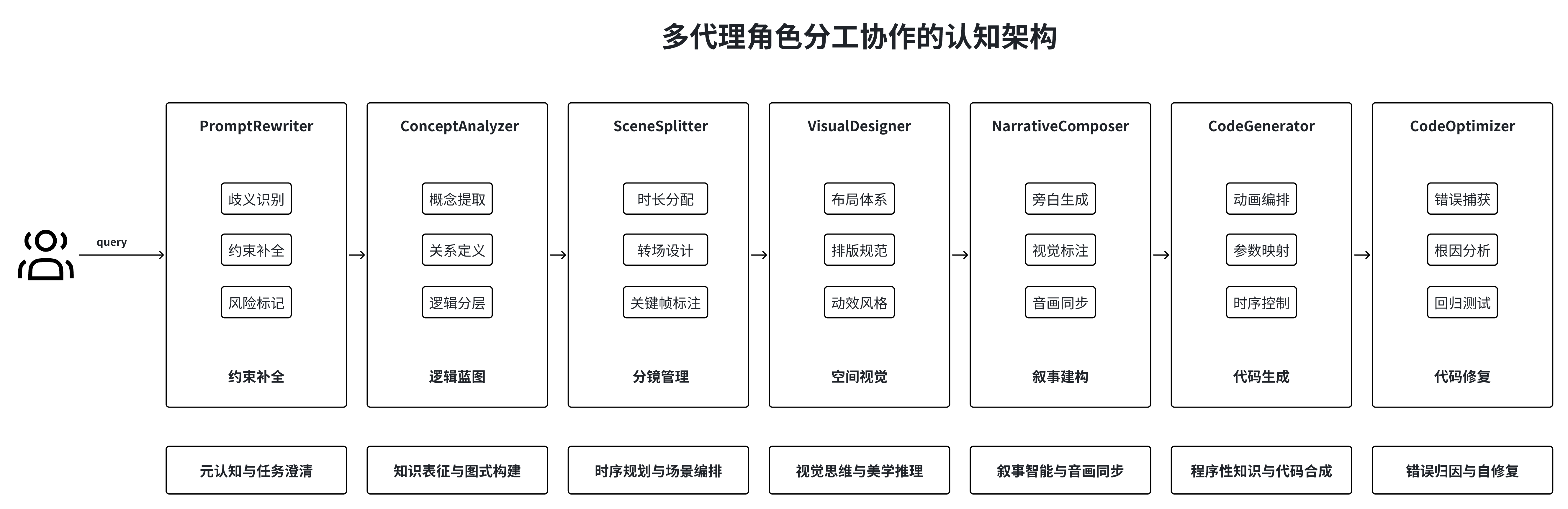
技术创新
系统架构总览
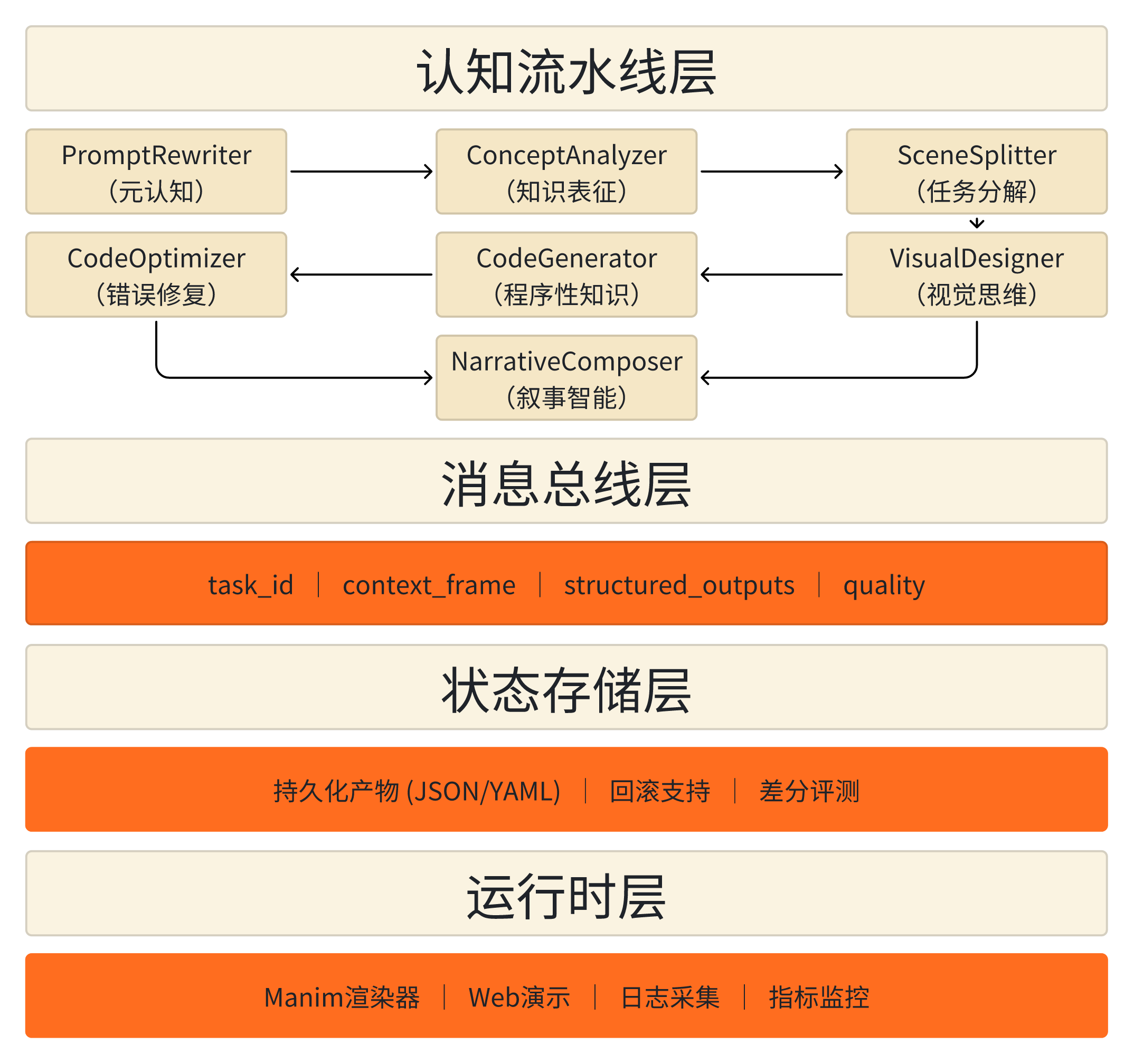
核心组件
智能体编排器
以DAG结构组织智能体执行,支持并行与选择性重执行,动态监测质量信号
消息总线
统一的任务令牌和上下文帧机制,所有消息遵循标准化Schema,确保可追溯、可审计
状态存储
持久化各阶段产物,支持回滚与跨迭代差分评测,维护完整执行历史链
运行时层
提供Manim渲染引擎、Web演示界面和全面日志系统,采集性能与成本数据
范式跃迁对比
| 维度 | 传统多步骤提示 | 本认知流水线 | 技术优势 |
|---|---|---|---|
| 执行结构 | 线性指令链 | DAG编排的智能体网络 | 吞吐提升2-3倍 |
| 知识传递 | 隐式上下文延续 | 结构化上下文帧 | 减少歧义传播 |
| 错误处理 | 全局重试或人工干预 | 阶段隔离调试+自动修复 | 修复迭代次数降至≤2 |
| 中间状态 | 不可见 | 可观测、可评估、可回滚 | 支持差分审计与质量量化 |
| 可扩展性 | 线性复杂度增长 | 模块化复用+并行化 | 新场景接入成本降低60% |